Systeemtabellen (RCB | BCB)

(G_SCI) Collectieclusters
Collecties kunnen vanuit diverse invalshoeken ingedeeld worden. Elke invalshoek heet een 'cluster'. Een indeling kan bijvoorbeeld de bestaande Genre/Siso-tabel zijn, maar kan ook vrij opgebouwd worden.
Iedere collectieclusterindeling kan uit meerdere groepen (clusters) bestaan; iedere groep (cluster) bestaat weer uit een of meerdere scat-codes (de statistische codes eventueel in combinatie met materiaalcodes).
Voorbeeld:
In dit vereenvoudigd voorbeeld wordt uitgegaan van de volgende scats:
Fictie:
1010 Familieromans
1020 Detectives
1030 Science Fiction
Non-Fictie:
2010 Sport
2020 Koken
2030 Tuin
Maak een indeling aan met 2 clusters Fictie en Non-fictie:
- Cluster Fictie bevat scatcodes 1010, 1020 en 1030
- Cluster Non-fictie bevat scatcodes 2010, 2020 en 2030
Met deze collectieclusterindeling kunnen analyses gemaakt worden op genre/siso niveau.
Een indeling kent de parameter Scat of Kast, is het collectiecluster (SCI) opgebouwd met scatcodes of kastcodes..
Een indeling en cluster (scatcodes gegroepeerd) kent de volgende parameters:
- Norm Uitleenfrequentie: Uitleenfrequentie die gewenst wordt bij een RCB-analyse volgende de “norm”-methode (zie Rapporten - RCB-analyse) (default = 6).
- Norm Aanschafperc.: Aanschafpercentage dat gewenst wordt bij een RCB-analyse volgende de “norm”-methode (zie Rapporten - RCB-analyse) (default = 12,5)
- Norm Afschrijfperc.: Afschrijfpercentage dat gewenst wordt bij een RCB-analyse volgende de “norm”-methode (zie zie Rapporten - RCB-analyse) (default = 12,5)
De bovenstaande parameters bij de cluster worden als default gebruikt indien bij een groep niets is opgegeven.
Eén van deze clusters gaat de basis voor de besteladviezen vormen. Mogelijk voldoen bestaande indelingen niet aan de daarvoor bestaande wensen en moet hier een apart cluster aangemaakt worden met geheel nieuwe groepen.
Tip: Voor het opbouwen van een collectiecluster is een Excel-format beschikbaar. Deze kan geïmporteerd worden in OCLC Wise.
Collectiecluster aanmaken
Klik op Nieuw en het volgende scherm verschijnt:
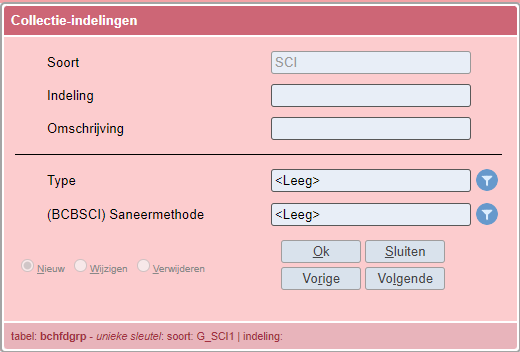
| Veld | Uitleg |
|---|---|
| Soort | Automatisch ingevuld |
| Indeling | Vul een drie-cijferige code in |
| Omschrijving | Geef het collectiecluster een omschrijving |
| Type |
Kies tussen:
Maak je geen keuze, dan wordt automatisch 'S - Scat' ingevuld. |
| (BCBSCI) Saneermethode | Kies een Saneermethode. Deze methode wordt per default gebruikt voor alle onderliggende groepen waarin geen Saneermethode is gekozen. |
In het voorbeeld wordt gekozen voor Scat.

Klik vervolgens op 'Openen' en daarna 'Nieuw' om de indeling in te vullen. Het volgende scherm verschijnt:

Uit het voorbeeld hieronder is het 1ste cluster met non-fictie en fictie genomen.
Bij cluster: een getal invullen (max 4 posities) en vul fictie of non-fictie bij de omschrijving.
De volgende velden hoeven niet te worden ingevuld, maar kan wel.
Default staat ingesteld voor norm uitleenfrequentie 6, norm afschrijfpercentage 12.5% en norm aanschafpercentage 12,5%. Een uitleg van de gebruikte termen staat reeds eerder beschreven.
Telgroep: in welk (deel)budget moet de aanschaf worden geteld.
Resultaat:

Voor het vullen: open het cluster en vul het volgende scherm in.

| Veld | Uitleg |
|---|---|
| Code | Vul hier de scatcode in. Moeten bijvoorbeeld alleen de scatcodes die met een 1 beginnen worden meegenomen, vul dan alleen een 1 in. |
| Materiaal |
Vul hier de materiaalcode in. Een materiaalcode bestaat uit twee posities en er gaat een min-teken (–) aan vooraf. Sluit de materiaalcode regel af met een –, dat is de begrenzing. Als in een scat meerdere rmt’s zitten en deze hoeven niet allemaal in dit cluster, vul dan bij 'Materiaal' de gewenste codes in. Er mag geen komma tussen de codes zitten: -D2-U2- Of vul de eerste letter van het materiaal in gevolgd door een *. (G* betekent materiaalcode beginnend met een G: G1 tot en met GZ). |
| Omschrijving | Kies een omschrijving |
Afbeelding uit de praktijk
Er zijn 4 collectieclusters, de Cubiss indeling en 3 eigen clusters: kleine lijst, grote lijst en een indeling op hoofdgroepen. Een grove indeling op hoofdgroepen is veelal bedoeld voor het management.

Een bestaand collectiecluster kan gekopieerd worden.
Wijzigingen aanbrengen in een bestaand cluster:
Worden later (scat)clusters verwijderd of toegevoegd dan wordt dit meegenomen tijdens de procedure 'voortgang berekenen'. De voortgangsprocedure kan ook direct na het wijzigen worden uitgevoerd.
Rapporten van SCI – collectieclusters
Via Rapport in de bovenbalk is een overzicht te maken van de instellingen/parameters.
Vink op het eerste niveau met Soort en alle indelingen in beeld aan welke gegevens gewenst zijn (soort, indeling, omschrijving, type en/of saneermethode). Het rapport geeft de gekozen gegevens weer:
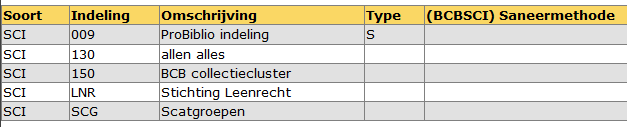
Op het tweede niveau met Soort, gekozen indeling en Cluster in beeld geeft het rapport de details van het cluster weer: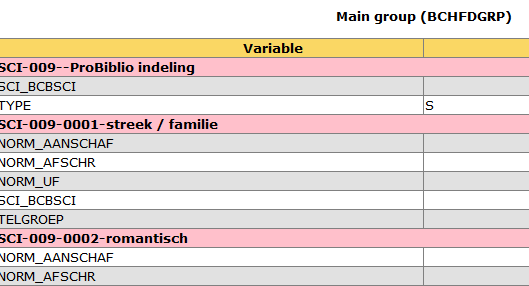
Op het laatste niveau, na openen van een willekeurig cluster, geeft het rapport de inhoud van het cluster weer. Hier zijn dan de clusters met de daarin opgenomen scats te zien:

(G_VSI) Vestigingsclusters
De vestigingen kunnen vanuit diverse invalshoeken worden ingedeeld. Elke invalshoek heet 'cluster'. Zo'n cluster bestaat uit 1 of meer groepen. Dit kan naar eigen inzicht, bijv. naar basisbibliotheek/stichting of naar omvang/grootte. Doel van de vestigingsclustering is de vergelijkingsmogelijkheid via de statistische analyse.Dit hoeft dus niet samen te vallen met een bestelgroep (basisbibliotheek/stichting).
Ieder cluster kan uit meerdere groepen bestaan, iedere groep weer uit een of meer vestigingen.
Iedere vestiging mag maar 1 keer voorkomen binnen een indeling.
Voorbeeld:
Stel: er zijn 3 gemeentes: A, B en C. Elke gemeente heeft een hoofdvestiging (c voor centrale) en 2 filialen (1 en 2). Er kan nu een cluster 1 gemaakt worden met 3 groepen. In elke groep komt een gemeente:
Groep 1 bevat de vestigingen Ac, A1 en A2
Groep 2 bevat de vestigingen Bc, B1 en B2
Groep 3 bevat de vestigingen Cc, C1 en C2
Met deze cluster kunnen analyses gemaakt worden per gemeente, waarbij de centrale en filialen met elkaar worden vergeleken/geanalyseerd.
Nu kan cluster 2 gemaakt worden, waarbij alle hoofdvestigingen in één groep gezet worden, en alle filialen in één groep:
Groep 1 bevat : Ac, Bc en Cc
Groep 2 bevat : A1, A2, B1, B2, C1 en C2
Met deze clusters kunnen prestaties van de Centrales onderling met elkaar vergeleken worden en alle filialen onderling met elkaar.
Vestigingscluster aanmaken
Hier staat het volgende scherm:

Geef een nummer (max. 4 cijfers) aan de indeling en geef een duidelijke omschrijving, bv basisbibliotheken, grote vestigingen, kleine vestigingen.
In het voorbeeld is gekozen voor cluster 1.

Cluster 1 wordt in het voorbeeld gevormd door 3 groepen. Open daarvoor cluster 1.

Klik op Nieuw om de groepen in te vullen.

Per vestigings-cluster kan nog worden aangegeven of dit vestigingen zijn met “achtergrond” functie en t.b.v. de advisering of herdrukken geadviseerd mogen worden.
Open om Groep 1 te vullen met Ac, A1 en A2 deze groep, en voeg de 3 toe.
Resultaat:

Daarna is mhet mogelijk om Groep 2 te vullen met de vestigingen Bc, B1 en B2, en Groep 3 met Cc, C1 en C2.
Een 2de en volgende clusters kunnen gemaakt worden op dezelfde manier.
Afbeelding uit de praktijk:

Vestigingsgroep 002 is aangemaakt met de naam Basisbibliotheek.
Bij openen van indeling 002 worden de basisbibliotheken getoond.
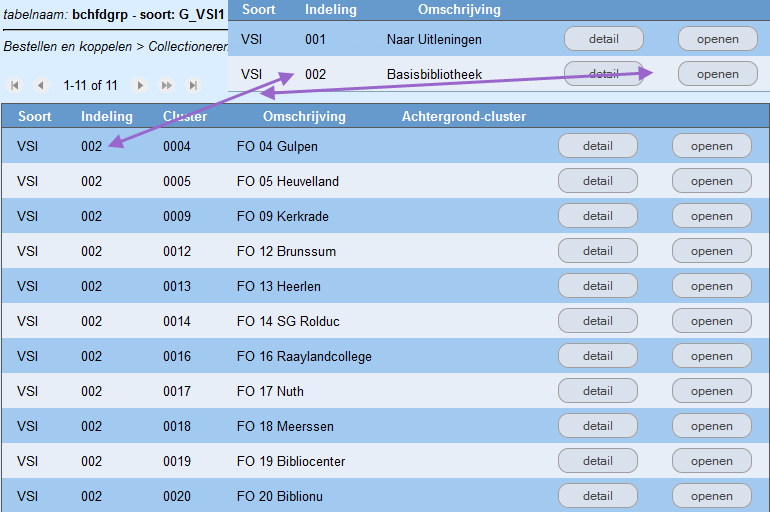
Bestaande vestigingsclusters zijn te kopiëren.
Bijzonderheden na inrichten
Wanneer een vestiging wordt toegevoegd aan een bestaand vestigingscluster, wordt deze niet automatisch in het collectieprofiel toegevoegd. De vestiging moet ook worden toegevoegd aan het CPI profiel.
Het kan voorkomen dat, door het toevoegen van 1 vestiging in het CPI, ook de andere nieuwe vestigingen direct toegevoegd worden zonder een extra handeling.
Is de naam van een vestiging gewijzigd, dan vervangt de nieuwe naam niet automatisch de naam in het CPI. De vestigingsnaam is namelijk de omschrijving gegeven bij het aanmaken van de vestigingscluster.
De nieuwe vestigingsnaam kan alleen via de querybrowser worden gewijzigd. Voor het wijzigen van de naam bij RCB/BCB kan contact worden opgenomen met OCLC via zendesk.
(TABNAV) Navigatieschema soorten
De navigatieschema's worden hier gedefinieerd.
Soort = NAV
Code = 1 cijfer of letter
Omschrijving = welke naam
De soorten zijn zichtbaar wanneer de licentie ‘navigatiemodule’ is gezet.
(TABBAN) BA moeilijkheidsgraad
Moeilijkheidsgraad : waarde van 1 t/m 5; 1 = zeer moeilijk, 5 = zeer eenvoudig
(TABBAP) BA populariteit
De populariteit : waarde van 1 t/m 5; 1 = geen vraag, 5 = zeer veel vraag / belangstelling.
NBD Biblion levert deze titelwaarderingen in de vorm van AA-staffels, zie TABBAS - NBD-staffel.
(TABBAO) BA kwaliteitsoordeel
Kwaliteitsoordeel : waarde van 1 t/m 5; 1 = zeer slecht/niet aanschaffen, 5 = zeer goed/aanschaffen.
NBD Biblion levert deze titelwaarderingen in de vorm van AA-staffels, zie TABBAS - NBD-staffel.
(TABBAS) NBD-staffel
De NBD levert titelwaarderingen in de vorm van AA-staffels. Deze staffel is opgebouwd uit een populariteitscijfer en kwaliteitsoordeel. Deze 2 waarden worden bij elkaar opgeteld en als 1 cijfer aangeleverd. De waarde ligt daarmee tussen 2 en 10. Wise leest deze staffel in verlaagd met 1, dus een waarde tussen 1 en 9.
Wise verwerkt dit als volgt :
| AA staffel | Populariteit | Oordeel |
|---|---|---|
|
10 |
5 |
5 |
|
9 |
4 |
5 |
|
8 |
4 |
4 |
|
7 |
3 |
4 |
|
6 |
3 |
3 |
|
5 |
2 |
3 |
|
4 |
2 |
2 |
|
3 |
1 |
2 |
|
2 |
1 |
1 |
Indien de moeilijkheidsgraad 1 of 2 is, dan wordt de populariteit met 1 verlaagd en het oordeel dus met 1 verhoogd.
Indien de titel in een Standing Order pakket zit, dan wordt de populariteit met 1 verhoogd en het oordeel dus met 1 verlaagd.
Waarderingen van Medio Europe
Medio Europe levert quoteringen in de vorm van letters.
Wise verwerkt dit als volgt:
|
Quotering |
Populariteit |
Oordeel |
|---|---|---|
|
AAA |
5 |
4 |
|
AA |
4 |
4 |
|
A |
4 |
3 |
|
B |
3 |
3 |
|
C |
2 |
3 |
(TABBAC) BA culturele waarde
Binnen collectiebeheer, bijv. bij afschrijfadviezen, speelt de culturele waarde (soms) een rol. In de client kan de culturele waarde bij een titel, een auteur, een onderwerp of een reeks worden opgegeven. BCB houdt er rekening mee.
|
1 |
pulp |
|
3 |
standaard |
|
5 |
bewaren |